KEGG pathway enrichment
Xiaotao Shen PhD (https://www.shenxt.info/)
Created on 2020-03-28 and updated on 2022-09-19
Source:vignettes/kegg_pathway_enrichment.Rmd
kegg_pathway_enrichment.RmdLoad KEGG pathway human database
data("kegg_hsa_pathway", package = "metpath")
kegg_hsa_pathway
#> ---------Pathway source&version---------
#> KEGG & 2021-12-13
#> -----------Pathway information------------
#> 345 pathways
#> 334 pathways have genes
#> 0 pathways have proteins
#> 281 pathways have compounds
#> Pathway class (top 10): Metabolism; Carbohydrate metabolism;Metabolism; Lipid metabolism
#>
get_pathway_class(kegg_hsa_pathway)
#> # A tibble: 43 × 2
#> class n
#> <chr> <int>
#> 1 Cellular Processes; Cell growth and death 8
#> 2 Cellular Processes; Cell motility 1
#> 3 Cellular Processes; Cellular community - eukaryotes 5
#> 4 Cellular Processes; Transport and catabolism 7
#> 5 Environmental Information Processing; Membrane transport 1
#> 6 Environmental Information Processing; Signal transduction 26
#> 7 Environmental Information Processing; Signaling molecules and interact… 5
#> 8 Genetic Information Processing; Folding, sorting and degradation 7
#> 9 Genetic Information Processing; Replication and repair 7
#> 10 Genetic Information Processing; Transcription 3
#> # … with 33 more rowsPathway enrichment
We use the demo compound list from metpath.
data("query_id_kegg", package = "metpath")
query_id_kegg
#> [1] "C00164" "C00099" "C00300" "C01026" "C00122" "C00037" "C05330" "C00097"
#> [9] "C00079" "C00065" "C00188" "C00082" "C00183" "C00166" "C00163" "C00022"
#> [17] "C00213"Remove the disease pathways:
#get the class of pathways
pathway_class =
metpath::pathway_class(kegg_hsa_pathway)
head(pathway_class)
#> $hsa00010
#> [1] "Metabolism; Carbohydrate metabolism"
#>
#> $hsa00020
#> [1] "Metabolism; Carbohydrate metabolism"
#>
#> $hsa00030
#> [1] "Metabolism; Carbohydrate metabolism"
#>
#> $hsa00040
#> [1] "Metabolism; Carbohydrate metabolism"
#>
#> $hsa00051
#> [1] "Metabolism; Carbohydrate metabolism"
#>
#> $hsa00052
#> [1] "Metabolism; Carbohydrate metabolism"
remain_idx =
pathway_class %>%
unlist() %>%
stringr::str_detect("Disease") %>%
`!`() %>%
which()
remain_idx
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#> [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
#> [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
#> [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
#> [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 90 91 92 93 94
#> [91] 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112
#> [109] 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130
#> [127] 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148
#> [145] 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166
#> [163] 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184
#> [181] 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202
#> [199] 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220
#> [217] 221 222 223 224 225 226 227 228 229 230 236 240 241 242 243 244 245 246
#> [235] 247 248 249 250 251 252 253 254
pathway_database =
kegg_hsa_pathway[remain_idx]
pathway_database
#> ---------Pathway source&version---------
#> KEGG & 2021-12-13
#> -----------Pathway information------------
#> 242 pathways
#> 235 pathways have genes
#> 0 pathways have proteins
#> 191 pathways have compounds
#> Pathway class (top 10): Metabolism; Carbohydrate metabolism;Metabolism; Lipid metabolism
#>
result =
enrich_kegg(query_id = query_id_kegg,
query_type = "compound",
id_type = "KEGG",
pathway_database = pathway_database,
p_cutoff = 0.05,
p_adjust_method = "BH",
threads = 3)Check the result:
result
#> ---------Pathway database&version---------
#> KEGG & 2021-12-13
#> -----------Enrichment result------------
#> 191 pathways are enriched
#> 28 pathways p-values < 0.05
#> Glycolysis / Gluconeogenesis;Citrate cycle (TCA cycle);Pentose phosphate pathway;Pentose and glucuronate interconversions;Fructose and mannose metabolism ... (only top 5 shows)
#> Plot to show pathway enrichment
enrich_bar_plot(object = result)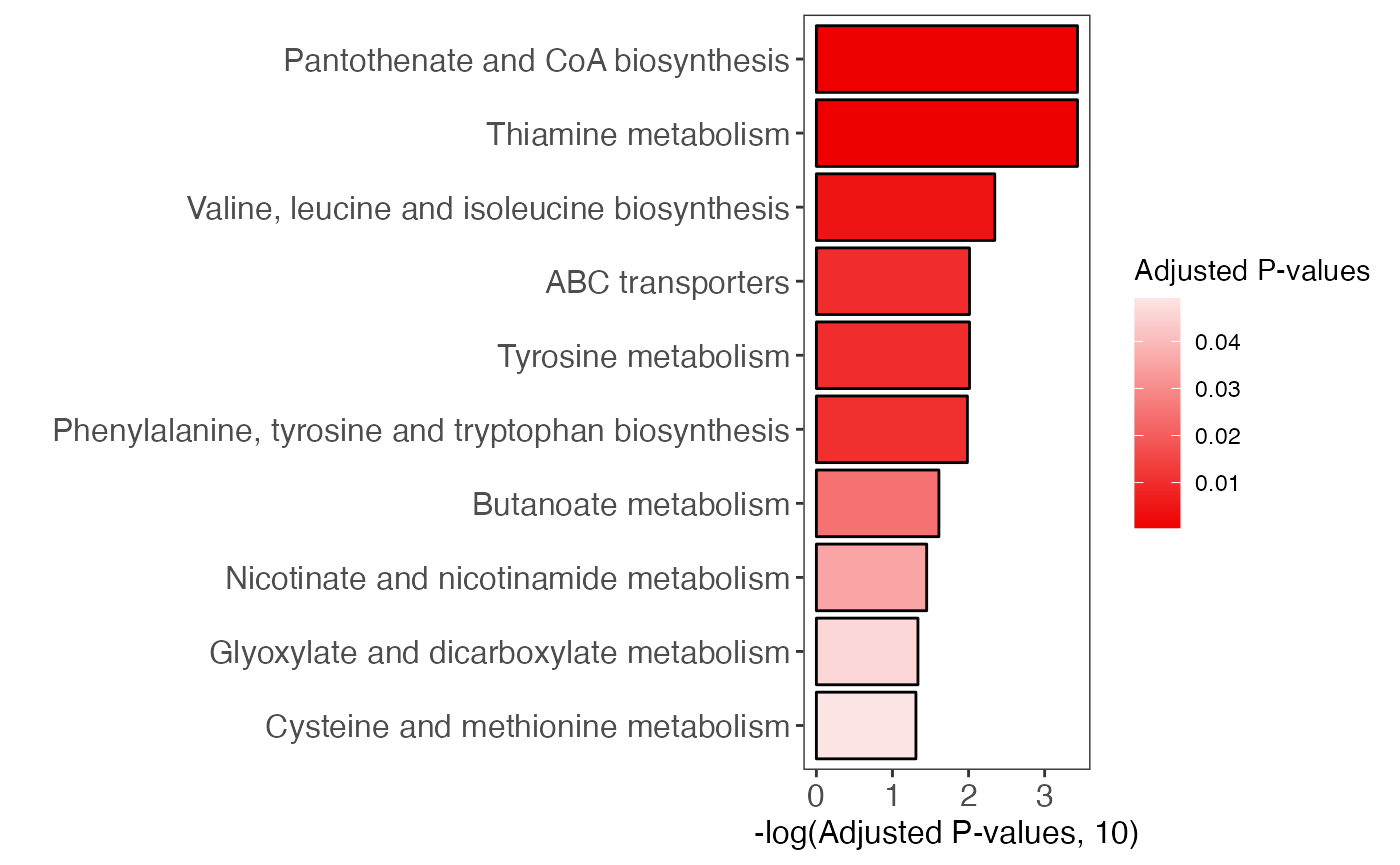
enrich_scatter_plot(object = result)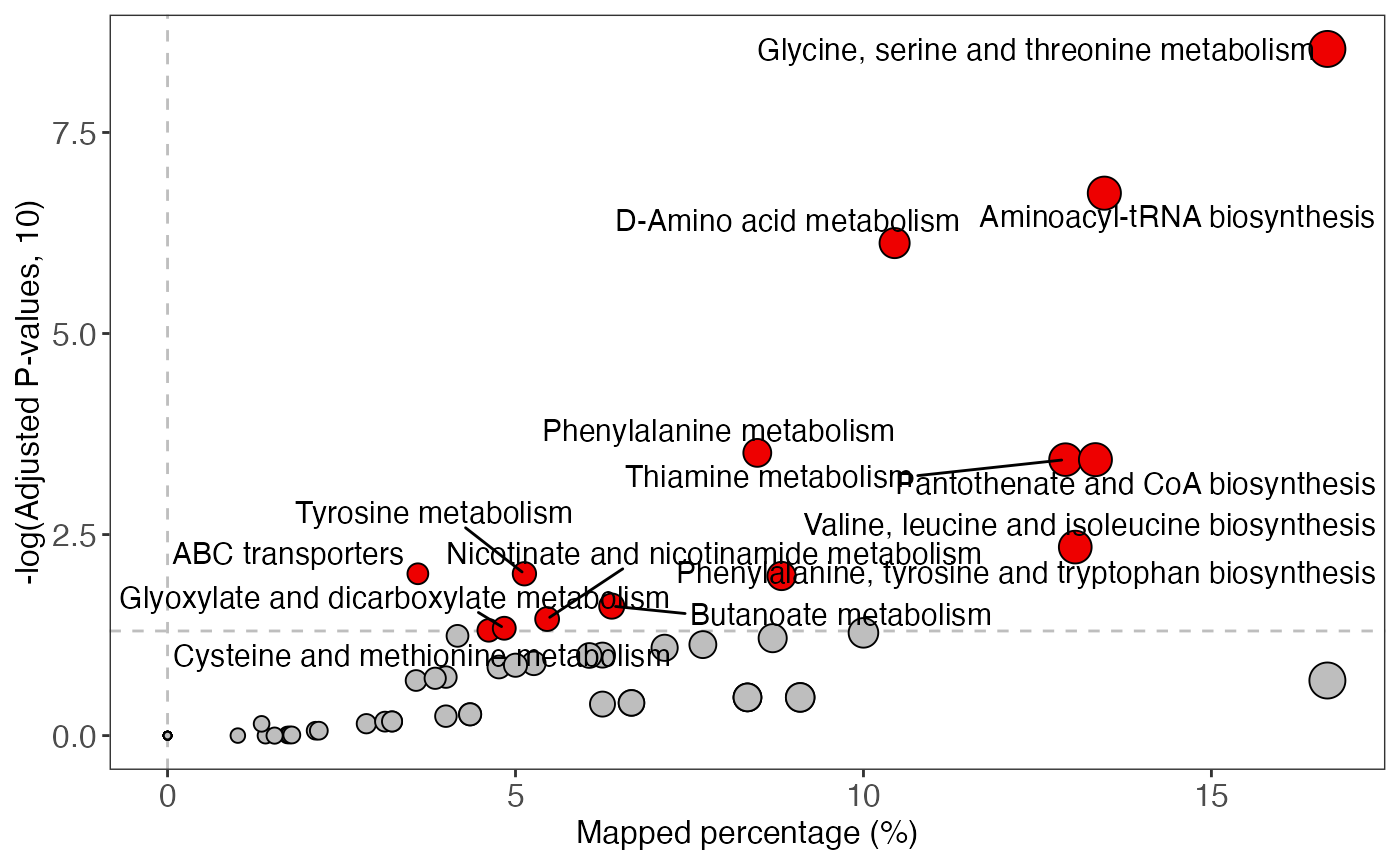
enrich_network(object = result)
Session information
sessionInfo()
#> R version 4.1.2 (2021-11-01)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Big Sur 10.16
#>
#> Matrix products: default
#> BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] forcats_0.5.1 stringr_1.4.0 dplyr_1.0.8 purrr_0.3.4
#> [5] readr_2.1.2 tidyr_1.2.0 tibble_3.1.6 ggplot2_3.3.5
#> [9] tidyverse_1.3.1 tinytools_0.9.1 massdataset_0.99.7 magrittr_2.0.2
#> [13] masstools_0.99.3 metid_1.2.1 metpath_0.99.2
#>
#> loaded via a namespace (and not attached):
#> [1] backports_1.4.1 circlize_0.4.14 readxl_1.3.1
#> [4] systemfonts_1.0.3 plyr_1.8.6 igraph_1.2.11
#> [7] lazyeval_0.2.2 BiocParallel_1.28.3 crosstalk_1.2.0
#> [10] listenv_0.8.0 leaflet_2.1.0 GenomeInfoDb_1.30.0
#> [13] digest_0.6.29 yulab.utils_0.0.4 foreach_1.5.2
#> [16] htmltools_0.5.2 viridis_0.6.2 fansi_1.0.2
#> [19] memoise_2.0.1 cluster_2.1.2 doParallel_1.0.17
#> [22] openxlsx_4.2.5 tzdb_0.2.0 limma_3.50.0
#> [25] ComplexHeatmap_2.10.0 globals_0.14.0 Biostrings_2.62.0
#> [28] graphlayouts_0.8.0 modelr_0.1.8 matrixStats_0.61.0
#> [31] pkgdown_2.0.2 colorspace_2.0-2 rvest_1.0.2
#> [34] ggrepel_0.9.1 haven_2.4.3 textshaping_0.3.6
#> [37] xfun_0.29 crayon_1.5.0 RCurl_1.98-1.5
#> [40] jsonlite_1.7.3 impute_1.68.0 iterators_1.0.14
#> [43] glue_1.6.1 polyclip_1.10-0 gtable_0.3.0
#> [46] zlibbioc_1.40.0 XVector_0.34.0 GetoptLong_1.0.5
#> [49] shape_1.4.6 BiocGenerics_0.40.0 scales_1.1.1
#> [52] vsn_3.62.0 DBI_1.1.2 Rcpp_1.0.8
#> [55] mzR_2.28.0 viridisLite_0.4.0 clue_0.3-60
#> [58] gridGraphics_0.5-1 preprocessCore_1.56.0 stats4_4.1.2
#> [61] MsCoreUtils_1.6.0 htmlwidgets_1.5.4 httr_1.4.2
#> [64] RColorBrewer_1.1-2 ellipsis_0.3.2 pkgconfig_2.0.3
#> [67] XML_3.99-0.8 farver_2.1.0 dbplyr_2.1.1
#> [70] sass_0.4.0 utf8_1.2.2 labeling_0.4.2
#> [73] ggplotify_0.1.0 tidyselect_1.1.1 rlang_1.0.1
#> [76] munsell_0.5.0 cellranger_1.1.0 tools_4.1.2
#> [79] cachem_1.0.6 cli_3.2.0 generics_0.1.2
#> [82] broom_0.7.12 evaluate_0.15 fastmap_1.1.0
#> [85] mzID_1.32.0 yaml_2.3.4 ragg_1.2.1
#> [88] knitr_1.37 fs_1.5.2 tidygraph_1.2.0
#> [91] zip_2.2.0 KEGGREST_1.34.0 ggraph_2.0.5
#> [94] ncdf4_1.19 pbapply_1.5-0 future_1.23.0
#> [97] xml2_1.3.3 compiler_4.1.2 rstudioapi_0.13
#> [100] plotly_4.10.0 png_0.1-7 affyio_1.64.0
#> [103] reprex_2.0.1 tweenr_1.0.2 bslib_0.3.1
#> [106] stringi_1.7.6 highr_0.9 desc_1.4.0
#> [109] MSnbase_2.20.4 lattice_0.20-45 ProtGenerics_1.26.0
#> [112] ggsci_2.9 vctrs_0.3.8 pillar_1.7.0
#> [115] lifecycle_1.0.1 furrr_0.2.3 BiocManager_1.30.16
#> [118] GlobalOptions_0.1.2 jquerylib_0.1.4 MALDIquant_1.21
#> [121] data.table_1.14.2 bitops_1.0-7 R6_2.5.1
#> [124] pcaMethods_1.86.0 affy_1.72.0 gridExtra_2.3
#> [127] IRanges_2.28.0 parallelly_1.30.0 codetools_0.2-18
#> [130] MASS_7.3-55 assertthat_0.2.1 rjson_0.2.21
#> [133] rprojroot_2.0.2 withr_2.4.3 S4Vectors_0.32.3
#> [136] GenomeInfoDbData_1.2.7 parallel_4.1.2 hms_1.1.1
#> [139] grid_4.1.2 rmarkdown_2.11 ggforce_0.3.3
#> [142] lubridate_1.8.0 Biobase_2.54.0